편향-분산 트레이드오프
이 문서는 다른 언어판 위키백과의 문서(en:Bias–variance_tradeoff)를 번역 중이며, 한국어로 좀 더 다듬어져야 합니다. |
통계학과 기계 학습 분야에서 말하는 편향-분산 트레이드오프(Bias-variance tradeoff) (또는 딜레마(dilemma))는 지도 학습 알고리즘이 트레이닝 셋의 범위를 넘어 지나치게 일반화하는 것을 예방하기 위해 두 종류의 오차(편향, 분산)를 최소화 할 때 겪는 문제이다.
- 편향은 학습 알고리즘에서 잘못된 가정을 했을 때 발생하는 오차이다. 높은 편향값은 알고리즘이 데이터의 특징과 결과물과의 적절한 관계를 놓치게 만드는 과소적합(underfitting) 문제를 발생 시킨다.
- 분산은 트레이닝 셋에 내재된 작은 변동(fluctuation) 때문에 발생하는 오차이다. 높은 분산값은 큰 노이즈까지 모델링에 포함시키는 과적합(overfitting) 문제를 발생 시킨다.




편향-분산 분해는 학습 알고리즘의 기대 오차를 분석하는 한 가지 방법으로, 오차를 편향, 분산, 그리고 데이터 자체가 내재하고 있어 어떤 모델링으로도 줄일수 없는 오류의 합으로 본다. 편향-분산 트레이드 오프는 분류(classification), 회귀분석[1][2], 그리고 구조화된 출력 학습 출력학습(structed output learning) 등 모든 형태의 지도 학습에 응용된다. 또한 사람의 학습에서 직관적 판단 오류(heuristics)의 효과성을 설명하기 위해 언급되기도 한다.
동기
편집-
 치우침 낮음, 분산 낮음
치우침 낮음, 분산 낮음 -
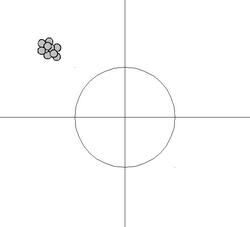 높은 편향, 분산 낮음:
높은 편향, 분산 낮음: -
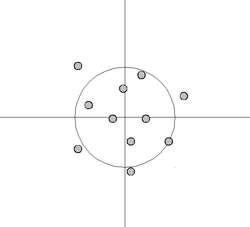 낮은 편향,분산 높음:
낮은 편향,분산 높음: -
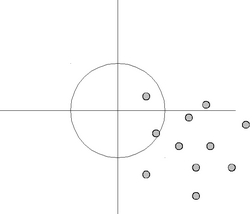 높은 편향,분산 높음:
높은 편향,분산 높음:




편향-분산 트레이드오프는 지도 학습에서 매우 중요한 문제이다. 모델을 선택할 때(model selection), 트레이닝 데이터의 규칙을 정확하게 포착하는 것 뿐만이 아니라, 보이지 않는 범위에 대해서 일반화(generalization)까지 하는 것이 이상적이다. 하지만 안타깝게도 이 둘을 동시에 완전히 성취하는 것은 사실상 불가능하다. 고분산 학습 알고리즘은 트레이닝 셋을 잘 표현하기는 하지만, 지나치게 큰 노이즈나 아예 부적절한 트레이닝 데이터까지 과적합(overfitting)할 위험이 있다. 반대로 고편향 학습 알고리즘은 과적합(overfitting) 문제가 거의 없는 단순한 모델을 제시하지만 트레이닝 데이터로부터 중요한 규칙성을 제대로 포착하지 못하는 과소적합(underfitting) 문제가 발생한다.
편향값이 낮은 모델은 일반적으로 더 복잡하기 때문에(예: 더 높은 차수의 회귀 다항식) 트레이닝 셋을 더 정확히 표현한다. 하지만 모델링 과정에서 커다란 노이즈 성분까지 반영할 가능성이 있고, 그런 경우에는 더 복잡함에도 불구하고 덜 정확한 추론을 하게 된다. 반대로 편향값이 높은 모델의 경우 간단한(낮은 차수의 회귀 다항식) 경향이 있는데, 트레이닝 셋의 데이터를 모델에 충분히 포함하지 못해 분산값이 낮게 나올 수가 있다.
제곱 오류의 편향-분산 분해
편집트레이닝 셋이 와 각 들에 대응되는 들의 쌍으로 표현되는 점들의 집합이라고 하자. 우리는 여기에 노이즈가 낀 함수적인 관계가 있다고 가정하고, 그 관계를 할 것이다. 여기에서 은 평균이 0이고 분산이 인 정규 분포이다.






우리는 실제 관계함수인 를 학습 알고리즘을 통해 최대한 잘 근사한 근사함수 를 찾고자 한다. 여기에서 말하는 "최대한 잘"이란 정량적으로 와 사이의 평균 제곱 오류(mean squared error)를 측정하여 그 값이 가장 작은 것을 찾는 것을 말한다. 얻어진 근사함수가 트레이닝 데이터 셋 내부의 평균제곱오차 뿐만이 아니라 외부로 일반화 된 범위에서도 평균제곱오차가 최소라면 이상적일 것이다. 하지만 에 라는 노이즈가 내재된 만큼 우리가 어떤 함수를 찾아내든 오차는 불가피하다.



트레이닝 셋의 범위를 넘어선 점들까지 일반화하는 를 찾기 위해서는 지도 학습에 관한 수많은 알고리즘들을 사용하면 된다. 우리가 어떤 를 선택하든 보이지 않는 표본 에 관한 기대 오차는 다음과 같이 분해할 수 있다:[3]:34[4]:223


![{\displaystyle {\begin{aligned}\mathrm {E} {\Big [}{\big (}y-{\hat {f}}(x){\big )}^{2}{\Big ]}&=\mathrm {Bias} {\big [}{\hat {f}}(x){\big ]}^{2}+\mathrm {Var} {\big [}{\hat {f}}(x){\big ]}+\sigma ^{2}\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/328075a763fe06d0201748100d57b53bd85a89db)
여기에서 편향(bias)은
![{\displaystyle {\begin{aligned}\mathrm {Bias} {\big [}{\hat {f}}(x){\big ]}=\mathrm {E} {\big [}{\hat {f}}(x)-f(x){\big ]}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5acc7f11d38f737d9c32d537eb0006945e5dc95e)
이고, 분산(var)은
![{\displaystyle {\begin{aligned}\mathrm {Var} {\big [}{\hat {f}}(x){\big ]}=\mathrm {E} {\Big [}{\big (}{\hat {f}}(x)-\mathrm {E} [{\hat {f}}(x)]{\big )}^{2}{\Big ]}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c938173fc2d2ac97408bdec7d318b3594285a76a)
이다.
위 식의 기댓값은 동일한 분포에서 트레이닝 셋 을 어떤 식으로 다르게 추출하느냐에 따라 달라진다. 세 항은 각각 다음을 의미한다:

- 편향(bias) 제곱 항은 모델을 간소화 하면서 하는 가정이 잘못됐을때(비선형인데 선형 모형을 세울때)나타나는 것으로, 편향값이 존재하면 를 세울 때 사용한 가정에 오류가 존재한다는 뜻이다.
- 분산(var)값은 가 그 평균에서 근처에서 얼마만큼의 폭으로 변동하느냐를 나타낸다.
- 는 줄일 수 없는 오차를 뜻하며, 모든 항의 값이 0 이상이므로 이 항은 보이지 않는 표본들의 기대오차의 하한값의 역할을 한다.[3]:34
가 복잡할수록 더 많은 데이터들을 포착할 수 있어서 편향값이 작아지지만 모델이 각 점을 포착하기 위해 더 많이 '움직여야'하므로 그만큼 분산값은 커지게 된다.
**** 수식이 부주의 하게 사용 됨.
예를 들어 설명변수 x0 에 해당하는 여러개의 관측값( y01, y02 ... )있을 경우 y01 , y02... 의 평균은 f0 일 것이다. (오차항의 평균은 0라고 했으니) 그리고 관측값 정확히 예측하는 f^_1 , f^_2 , .... 이 있다면
위수식에서 MSE항 , E[ (y-f^)^2 ] = 0 (이 수식은 관측값과 예측값의 차이를 제곱하는데 정확히 관측값을 예상하므로)
또 Bias 항은 E[f^) - E(f) = E(y) - f = f -f = 0 (관측값은 평균은 리얼값이다.)
나머지 분산항은 E[ (y - E[y])^2] 이 되는데 E[y] = f 임을 생각하면 결국 E(y-f)^2] 가 된다. ( 오차항의 분산)
다시말해 위 수식은 (관측치를 정확하게 예상하는 예측치가 있다면) MSE = 0 , Bias = 0 , var = 오차항의 분산 이된다.
수식에서 MSE는 오차항의 분산이 빠져 있고 분산항은 오차항의 분산을 포함하고 있는 상태이다.
(수식대로 계산하면 수식의 우변이 좌변보다 2*오차항의 분산 만큼 크다)
수식을 수정하자면
MSE항의 y(관측값)를 f(실제값, 이상값)로 바꾸면 오차항을 포함하는 수식이 되고
분산항 Var[f^] + 오차항의 분산 = E[ 위와 값은 ] 로 바꾸면 된다.
유도
편집제곱 오류를 편향-분산 분해하는 과정의 유도는 다음과 같이 할 수 있다. 편의를 위해 그리고 로 두겠다. 우선 확률 변수 에 대해



![{\displaystyle {\begin{aligned}\mathrm {E} [X^{2}]&=\mathrm {E} [X^{2}]-\mathrm {E} [2X\mathrm {E} [X]]+\mathrm {E} [\mathrm {E} [X]^{2}]+\mathrm {E} [2X\mathrm {E} [X]]-\mathrm {E} [\mathrm {E} [X]^{2}]\\&=\mathrm {E} [X^{2}-2X\mathrm {E} [X]+\mathrm {E} [X]^{2}]+2\mathrm {E} [X]^{2}-\mathrm {E} [X]^{2}\\&=\mathrm {E} [(X-\mathrm {E} [X])^{2}]+\mathrm {E} [X]^{2}\\&=\mathrm {Var} [X]+\mathrm {E} [X]^{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e611316ca4b67923a654f428e15005cebee47475)
이고, 의 값들은 결정되어있으므로

![{\displaystyle {\begin{aligned}0=\mathrm {Var} [f]=\mathrm {E} [(f-\mathrm {E} [f])^{2}]\Rightarrow f-\mathrm {E} [f]=0\Rightarrow \mathrm {E} [f]=f\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/010bbebbf8e7c605d6fef8e7d509d5810f635db9)
가 성립한다.
주어진 조건 과 으로부터 가 성립한다.

![{\displaystyle \mathrm {E} [\epsilon ]=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f7494dee92fe5ac5a8d8a61fa72e73482ad679d9)
![{\displaystyle \mathrm {E} [y]=\mathrm {E} [f+\epsilon ]=\mathrm {E} [f]=f}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6a027bc2f4ced7f9af72c462a548d72d285aa788)
그리고 이므로,
![{\displaystyle \mathrm {Var} [\epsilon ]=\sigma ^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4ed97af78f7548bb5ebb8ae3a04101a3c8a25511)
![{\displaystyle {\begin{aligned}\mathrm {Var} [y]=\mathrm {E} [(y-\mathrm {E} [y])^{2}]=\mathrm {E} [(y-f)^{2}]=\mathrm {E} [(f+\epsilon -f)^{2}]=\mathrm {E} [\epsilon ^{2}]=\mathrm {Var} [\epsilon ]+\mathrm {E} [\epsilon ]^{2}=\sigma ^{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/459eaadae3f6c660fbefa85b4c14ef1d3e78c444)
와 는 서로 독립적이므로,
![{\displaystyle {\begin{aligned}\mathrm {E} {\big [}(y-{\hat {f}})^{2}{\big ]}&=\mathrm {E} [y^{2}+{\hat {f}}^{2}-2y{\hat {f}}]\\&=\mathrm {E} [y^{2}]+\mathrm {E} [{\hat {f}}^{2}]-\mathrm {E} [2y{\hat {f}}]\\&=\mathrm {Var} [y]+\mathrm {E} [y]^{2}+\mathrm {Var} [{\hat {f}}]+\mathrm {E} [{\hat {f}}]^{2}-2f\mathrm {E} [{\hat {f}}]\\&=\mathrm {Var} [y]+\mathrm {Var} [{\hat {f}}]+(f-\mathrm {E} [{\hat {f}}])^{2}\\&=\sigma ^{2}+\mathrm {Var} [{\hat {f}}]+\mathrm {Bias} [{\hat {f}}]^{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cffbb06bfbf75c088ff4e6d47356da1e9609f54a)
가 성립한다.
분류에서의 응용
편집편향-분산 분해는 본래 최소 제곱 회귀(least-squares regression)를 위해 만들어졌다. 0-1 이하 손실 분류(classification)(오분류 확률)의 경우, 유사한 분해가 가능하다.[5][6] 대신에, 만약 분류 문제가 확률적 분류(probabilistic classification)로 표현될 수 있다면, 실제 확률에 의한 예상 확률의 기대 제곱 오류(expected squared error)가 기존처럼 분해될 수 있다.[7]
접근 방법
편집차원 축소(dimensionality reduction)와 특징 선택(feature selection)은 모형 간소화에 의해 분산을 감소시킨다. 유사하게, 트레이닝 셋이 클수록 분산이 작아진다. 특징을 추가할수록 추가적인 분산의 도입으로 편향이 작아진다. 학습 알고리즘은 보통 편향과 분산을 제어하는(control) 조정 가능한(tunable) 다음과 같은 매개 변수들을(parameters) 갖는다.
- 일반적인 선형 모형(generalized linear models)은 편향을 증가시켜 규칙화(regularize)할 수 있다.
- 인공신경망(artificial neural networks)에서 은닉 단위(hidden units) 개수가 증가할수록 분산은 증가하고 편향은 감소한다.[1] 일반적인 선형 모형(GLMs)에서처럼 규칙화(regulaization)도 적용된다.
- K-근접이웃(K-nearest neighbor) 모형에서 가 클수록 편향은 증가하고 분산은 감소한다.
- 인스턴스 기반 학습(instance-based learning)에서 프로토타입(prototypes)과 견본(exemplars)의 조합을 다양하게 함으로써 규칙화할 수 있다.[8]
- 의사결정나무(decision tree)에서 깊이(depth)는 분산을 결정한다. 의사결정나무는 일반적으로 분산을 제어하기 위해 가지를 친다(pruned).[3]:307

트레이드오프를 해결하는 하나의 방법으로 혼합모형(mixture models)과 앙상블 학습(ensemble learning)이 있다.[9][10]
K-근접이웃
편집K-근접이웃 회귀 알고리즘의 경우, 편향-분산 분해와 매개 변수 를 관련짓는 닫힌 형식의 수식(closed-form expression)이 존재한다.[4]:37, 223
![{\displaystyle \mathrm {E} [(y-{\hat {f}}(x))^{2}]=\left(f(x)-{\frac {1}{k}}\sum _{i=1}^{k}f(N_{i}(x))\right)^{2}+{\frac {\sigma ^{2}}{k}}+\sigma ^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2852b9b12eb56a64c35b4eb49b9e3b19b665da2f)
여기서 는 트레이닝 셋에서 의 -근접이웃들이다. 편향(첫 번째 항)은 의 단조증가함수(monotone increasing function)이고, 분산(두 번째 항)은 이 증가할수록 감소한다. 실제로 합리적 추론하에 가장 가까운 이웃 추정자의 편향은 트레이닝 셋의 사이즈가 무한에 근접해야 완전히 사라진다.[1]

인간 학습에서의 적용
편집편향-분산 딜레마는 기계 학습의 맥락에서 많이 논의되어 왔으며, 인간 인지의 맥락에서는 주로 "Gerd Gigerenzer"와 그의 동료들에 의해 학습된 발견적 교수법(heuristics)의 관점으로 조사되어왔다. 그들은 인간의 뇌가 경험으로부터 전체적으로 희박하고 형편없이 특징지어진 트레이닝 셋을 제공받았을 때의 딜레마를 고편향/저분산의 발견적 교수법을 취함으로써 해결한다고 주장하였다. 이것은 제로-편향의 접근이 새로운 상황에 대해 형편없는 일반화가능도를 가지며 환경의 진짜 상태에 대한 정확한 지식을 비이성적으로 추정한다는 사실을 나타낸다. 결과적으로 나타난 발견적 교수법은 비교적 간단하지만, 다양한 상황들에 대해 더 나은 추론을 생산한다.[11]
"Getman et al."[1] 은 편향-분산 딜레마가 포괄적 물체 인식같은 능력들이 스크래치(scratch)로부터 학습될 수 없고, 나중에 경험으로부터 조정되는 어느 정도의 "hard wiring"이 필요하다는 것을 암시한다고 주장하였다. 이것은 모델프리(model-free) 접근법으로 추론하는 것이 높은 분산을 피하기 위해서 실현 불가능할 정도로 많은 트레이닝 셋을 필요로 하기 때문이다.
같이 보기
편집각주
편집- ↑ 가 나 다 라 Geman, Stuart; E. Bienenstock; R. Doursat (1992). “Neural networks and the bias/variance dilemma” (PDF). 《Neural Computation》 4: 1–58. doi:10.1162/neco.1992.4.1.1.
- ↑ Bias–variance decomposition, In Encyclopedia of Machine Learning. Eds. Claude Sammut, Geoffrey I. Webb. Springer 2011. pp. 100-101
- ↑ 가 나 다 Gareth James; Daniela Witten; Trevor Hastie; Robert Tibshirani (2013). 《An Introduction to Statistical Learning》. Springer. 2019년 6월 23일에 원본 문서에서 보존된 문서. 2015년 4월 27일에 확인함.
- ↑ 가 나 Hastie, Trevor; Tibshirani, Robert; Friedman, Jerome (2009). 《The Elements of Statistical Learning》. 2015년 1월 26일에 원본 문서에서 보존된 문서. 2015년 4월 27일에 확인함.
- ↑ Domingos, Pedro (2000). 《A unified bias-variance decomposition》 (PDF). ICML.
- ↑ Valentini, Giorgio; Dietterich, Thomas G. (2004). “Bias–variance analysis of support vector machines for the development of SVM-based ensemble methods”. 《JMLR》 5: 725–775.
- ↑ Manning, Christopher D.; Raghavan, Prabhakar; Schütze, Hinrich (2008). 《Introduction to Information Retrieval》. Cambridge University Press. 308–314쪽.
- ↑ Gagliardi, F. (2011) "Instance-based classifiers applied to medical databases: diagnosis and knowledge extraction". Artificial Intelligence in Medicine. Volume 52, Issue 3 , Pages 123-139. http://dx.doi.org/10.1016/j.artmed.2011.04.002
- ↑ Jo-Anne Ting, Sethu Vijaykumar, Stefan Schaal, Locally Weighted Regression for Control. In Encyclopedia of Machine Learning. Eds. Claude Sammut, Geoffrey I. Webb. Springer 2011. p. 615
- ↑ Scott Fortmann-Roe. Understanding the Bias–Variance Tradeoff. 2012. http://scott.fortmann-roe.com/docs/BiasVariance.html
- ↑ Gigerenzer, Gerd; Brighton, Henry (2009). “Homo Heuristicus: Why Biased Minds Make Better Inferences”. 《Topics in Cognitive Science》 1: 107–143. doi:10.1111/j.1756-8765.2008.01006.x. PMID 25164802.